이 글은 새로운 블로그로 옮겼습니다. 5초후 자동으로 이동합니다.
▶ 새로운 블로그 주소: https://prodskill.com/
▶ 새로운 글 주소: https://prodskill.com/job-scheduling-using-1d-bin-packing-algorithm-2/
목차
2. 1차원 Bin Packing 알고리즘
2.1. 1차원 Bin Packing 알고리즘 종류
Bin Packing의 4가지 대표적 알고리즘은 다음과 같다.
- Next Fit: 마지막 Bin 또는 새로운 Bin에 채우기
- First Fit: 항상 처음 Bin 부터 탐색하여 채우기
- Worst Fit: 전체 Bin 중에서 남은 크기가 가장 크면서 현재 Item을 채울 수 있는 Bin을 탐색하여 채우기
- Best Fit: 전체 Bin 중에서 남은 크기가 가장 작으면서 현재 Item을 채울 수 있는 Bin을 탐색하여 채우기
덧붙여서, 전체 Item을 크기 내림차순(Descending)으로 정렬하고 각 알고리즘을 적용하면 훨씬 더 최적화된 결과를 얻을 수 있다. 내림차순 정렬을 적용하는 방법까지 고려하면 총 8가지의 알고리즘이 있다고 할 수 있다.
설명을 위하여 다음의 입력과 제약조건을 사용한다. (입력의 Item 명칭은 생략하고 크기만 기술함)
입력자료: 26 57 18 8 45 16 22 29 5 11 8 27 54 13 17 21 63 14 16 45 6 32 57 24 18 27 54 35 12 43 36 72 14 28 3 11 46 27 42 59 26 41 15 41 68
제약조건: 80 (Bin 하나의 최대 크기)
* 참고: 이 사례 데이터와 제약조건은 http://www.developerfusion.com/article/5540/bin-packing/ 에서 다운로드 받을 수 있는 Bin Packing Sample Application의 기본 데이터를 그대로 사용하였다. 이 sample application의 화면은 다음과 같다.
Bin Packing - VB.NET tutorial - developer Fusion
www.developerfusion.com

각 알고리즘의 pseudo code(의사코드)와 처리과정, 실행 결과를 자세하게 살펴보자.
2.2. Next Fit 알고리즘
각 item에 대해 마지막 Bin에 채울 수 있으면 채우고 채울 수 없으면 새로운 Bin을 만들어 채우는 방법이다. Next Fit은 가장 간단하지만 결과는 최적이라고 하기 어렵다.
// Pseudo code
item(1)을 새로운 Bin(1)에 채운다.
for (i=2; i<=item 개수; i++) {
j = 마지막 Bin index
if (item(i).Size <= Bin(j).남은공간Size) {
Bin(j)에 item(i)를 채운다;
}
else {
새로운 Bin(j+1)을 생성하고 item(i)를 채운다;
}
}입력자료: 26 57 18 8 45 16 22 29 5 11 8 27 54 13 17 21 63 14 16 45 6 32 57 24 18 27 54 35 12 43 36 72 14 28 3 11 46 27 42 59 26 41 15 41 68위 입력 값들 중 <10>번째까지의 과정을 아래에서 그림으로 살펴보자.

첫번째 입력 값 <26>은 새로운 Bin1을 만들고 여기에 채운다.

두번째 입력 값 <57>은 Bin(1)의 남은 크기(54)보다 커서 채울 수 없으므로 새로운 Bin(2)를 만들어 채운다.

세번째 입력 값 <18>은 현재 Bin(2)의 남은 크기(23)보다 작으므로 Bin(2)에 채운다.

네번째 입력 값 <8> 은 현재 Bin(2)의 남은 크기(5)보다 커서 채울 수 없으므로 새로운 Bin(3)을 만들어 채운다. 여기에서 알 수 있듯이 Next Fit 방법은 이미 지나온 Bin에 남는 공간이 있더라도 사용하지 않는다. 따라서, 공간의 낭비가 많이 발생할 수 있다.

다섯 번째 입력 값 <45>는 현재 Bin(3)의 남은 크기(72)보다 작으므로 Bin(3)에 채운다.

여섯 번째 입력 값 <16>은 현재 Bin(3)의 남은 크기(27)보다 작으므로 Bin(3)에 채운다.

일곱 번째 입력 값 <22>는 Bin(3)의 남은 크기(11)보다 커서 채울 수 없으므로 새로운 Bin(4)를 만들어 채운다.

여덟 번째 입력 값 <29>는 현재 Bin(4)의 남은 크기(58)보다 작으므로 Bin(4)에 채운다.
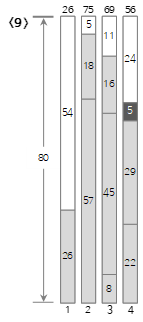
아홉 번째 입력 값 <5>는 현재 Bin(4)의 남은 크기(29)보다 작으므로 Bin(4)에 채운다.

열 번째 입력 값 <11>은 현재 Bin(4)의 남은 크기(24)보다 작으므로 Bin(4)에 채운다.
Next Fit 방식으로 마지막 item까지 계속 채우면 다음과 같은 결과를 얻을 수 있다. (Bin Packing Sample Application의 결과 화면)

Next Fit 방식의 결과는 위 그림에서 볼 수 있듯이 공간의 낭비가 커서 최적의 결과로 보기는 어렵다. 하지만, 반복 횟수가 적어서 실행 속도가 빠른 장점이 있다. 전체 공간은 1,840(Bin 하나당 크기 80 * Bin 개수 23)이고, 잔여공간합계는 488로 공간비효율은 약 26.52% (488/1,840) 이다.
2.3. First Fit 알고리즘
각 item에 대해 Bin 전체에 채울 수 있는지 확인하여 채울 수 있는 첫번째 Bin에 채우고, 채울 수 없으면 새로운 Bin을 만들어 채우는 방법이다.
// Pseudo code
item(1)을 새로운 Bin(1)에 채운다.
for (i=2; i<=item 개수; i++) {
for (j=1; j<=Bin갯수: j++) { // 항상 처음 Bin부터
if (item(i).Size <= Bin(j).남은공간Size) {
// item(i)를 채울 수 있는 Bin(j) 탐색
Bin(j)에 item(i)를 채운다;
exit for;
}
}
if (마지막 Bin까지 탐색해도 채울 수 없었으면) {
새로운 Bin(j+1)을 생성하고 item(i)를 채운다;
}
}입력자료: 26 57 18 8 45 16 22 29 5 11 8 27 54 13 17 21 63 14 16 45 6 32 57 24 18 27 54 35 12 43 36 72 14 28 3 11 46 27 42 59 26 41 15 41 68
위 입력 자료 중 First Fit 방식으로 처음 10개까지 채우는 과정은 다음 그림과 같다.

이 방법으로 전체 입력 자료를 채우면 다음과 같은 결과를 얻을 수 있다. (Bin Packing Sample Application의 결과 화면)

First Fit 방식은 Next Fit 보다 공간의 낭비가 적고 Bin의 개수가 더 적어 전체 공간이 작은 장점이 있다. 하지만 상대적으로 반복 횟수가 많아서 실행시간은 오래 걸리는 것은 단점이다. 전체 공간은 1,520(Bin 하나당 크기 80 * Bin 개수 19)이고, 잔여공간합계는 168로 공간비효율은 약 11.05% (168/1,520) 이다.
2.4. Worst Fit 알고리즘
각 item에 대해 모든 Bin 중에서 남은 크기가 가장 크면서 채울 수 있는 Bin에 채우고, 적합한 Bin이 없으면 새로운 Bin을 만들어 채우는 방법이다.
// Pseudo code
item(1)을 새로운 Bin(1)에 채운다;
for (i=2; i<=item갯수; i++) {
long lMaxRemainSize = 0;
long lMaxRemainSizeBinIndex = 0;
for (j=1; j<=Bin갯수: j++) {
// 남은공간Size가 가장 큰 Bin 탐색
if (lMaxRemainSize < Bin(j).남은공간Size) {
lMaxRemainSize = Bin(j).남은공간Size;
lMaxRemainSizeBinIndex = j;
}
}
if (item(i).Size <= Bin(lMaxRemainSizeBinIndex) {
// 남은공간Size가 가장 큰 Bin에 item(i)를 채울 수 있는 경우
Bin(lMaxRemainSizeBinIndex)에 item(i)을 채운다;
}
else {
새로운 Bin(j+1)을 생성하고 item(i)을 채운다;
}
}입력자료: 26 57 18 8 45 16 22 29 5 11 8 27 54 13 17 21 63 14 16 45 6 32 57 24 18 27 54 35 12 43 36 72 14 28 3 11 46 27 42 59 26 41 15 41 68
위 입력 자료 중 Worst Fit 방식으로 처음 10개까지 채우는 과정은 다음 그림과 같다.

그림에서 붉은색 item은 First Fit 방식과 채우는 방식이 다른 경우를 나타낸다.
이 방법으로 전체 입력 자료를 채우면 다음과 같은 결과를 얻을 수 있다. (Bin Packing Sample Application의 결과 화면)

Worst Fit 방식은 Next Fit보다는 공간 낭비가 적지만 First Fit 보다는 공간 낭비가 큰 편이다. 전체 공간은 1,680(Bin 하나당 크기 80 * Bin 개수 21)이고, 잔여공간합계는 328로 공간비효율은 약 19.52% (328/1,680) 이다.
2.5. Best Fit 알고리즘
각 item에 대해 모든 Bin 중에서 남은 크기가 가장 적으면서 해당 item을 채울 수 있는 Bin을 찾아 채우고, 적합한 Bin이 없으면 새로운 Bin을 만들어 채우는 방법이다.
// Pseudo code
for (i=2; i<=item갯수; i++) {
long lMinRemainSize = 제약조건으로 입력한 Bin의 최대 크기;
long lMinRemainSizeBinIndex = 0;
for (j=1; j<=Bin갯수: j++) {
// 남은공간Size가 가장 적으면서 item(i).Size를 채울 수 있는 Bin 탐색
if (oBin(j).남은공간Size >= item(i).SIze) and
(lMinRemainSize > oBin(j).남은공간Size)
lMinRemainSize = Bin(j).남은공간Size;
lMinRemainSizeBinIndex = j;
}
}
if (적합한 Bin을 찾았으면) {
Bin(lMinRemainSizeBinIndex)에 item(i)을 채운다;
}
else {
새로운 Bin(j+1)을 생성하고 item(i)을 채운다;
}
}입력자료: 26 57 18 8 45 16 22 29 5 11 8 27 54 13 17 21 63 14 16 45 6 32 57 24 18 27 54 35 12 43 36 72 14 28 3 11 46 27 42 59 26 41 15 41 68
위 입력 자료 중 Best Fit 방식으로 처음 10개까지 채우는 과정은 다음 그림과 같다.

그림에서 붉은색 item은 First Fit 방식과 채우는 방식이 다른 경우를 나타낸다. 과정을 First Fit, Worst Fit과 비교해 보면 방식을 확실하게 이해할 수 있다.
이 방법으로 전체 입력 자료를 채우면 다음과 같은 결과를 얻을 수 있다. (Bin Packing Sample Application의 결과 화면)

Best Fit 방식은 일반적으로 가장 최적화된 결과를 얻을 수 있지만, 반복 횟수가 많아서 실행 시간이 오래 걸리는 단점이 있다. 전체 공간은 1,520(Bin 하나당 크기 80 * Bin 개수 19)이고, 잔여공간합계는 168로 공간비효율은 약 11.05% (168/1,520) 이다.
First Fit과 Best Fit 방식의 결과가 동일한 Bin갯수, 동일한 잔여 공간인 것은 현재 예시로 사용하고 있는 입력 자료에서 독특하게 발생한 것이고 항상 동일하지는 않을 수 있다.
여기까지 각 알고리즘에 대해 살펴보았고, 다음에는 내림차순 정렬을 적용하는 방법과 각 알고리즘의 적용 결과를 비교하겠다.
'DA(Data Architecture) 도구 > 1차원 Bin Packing 도구' 카테고리의 다른 글
| 1차원 Bin Packing 알고리즘을 활용한 작업 배분 최적화 도구 설명글 전체 목차, 다운로드 (6) | 2021.06.20 |
|---|---|
| 1차원 Bin Packing 도구 최근 변경 사항 (2021-03-21 기준) (0) | 2021.06.12 |
| 1차원 Bin Packing 알고리즘을 활용한 작업 배분 최적화_4.별첨 (8) | 2021.05.22 |
| 1차원 Bin Packing 알고리즘을 활용한 작업 배분 최적화_3.구현(2) (0) | 2021.05.21 |
| 1차원 Bin Packing 알고리즘을 활용한 작업 배분 최적화_3.구현(1) (0) | 2021.05.21 |
| 1차원 Bin Packing 알고리즘을 활용한 작업 배분 최적화_2.알고리즘(2) (0) | 2021.05.20 |
| 1차원 Bin Packing 알고리즘을 활용한 작업 배분 최적화_1.개요 (2) | 2021.05.20 |
댓글